SOFTWARE LOCALISATION
Software localisation refers to the translation of a software interface and messages to another language while also adapting some formats (e.g. measures, dates, timezones, address information, names, currency, etc.) where necessary to meet requirements of the target cultures.
Software localisation, therefore, is more a complex process than the translation or localisation of simple textual documents, which implies terminological research, editing, proofreading and the modification of page layouts. Software localisation, in addition, tends to involve additional activities such as providing advice on translation strategies, converting file formats, multilingual software a testing, as well as multilingual product support. The main challenge for the translators, however, remains to provide a correct equivalent for each string in their native language without knowing the exact context. When working on an export that contains the individual text strings, they do not know whether they are translating a button, a menu, a tab, a message, a dialog box or any other type of GUI (Graphical User Interface) content. Allowing the translator to work within the software system itself is usually not an option. That is often too complicated, unsecure and not supported by state-of-art Computer Aided Translation tools. The latter also implies that all the benefits that come from Translation Memories, Terminology, workflow management, versioning and QA checks do not apply.
Untranslate proposes an innovative approach based on the Rigi cloud server, which provides a secure environment to manage software localisation projects. The technology allows for capturing dynamic previews of the software’s GUI. These previews are then used to provide context to the translators. This enables them to understand the meaning and function of each text string within the application, and shows them the available space the equivalent translation must fit into. Furthermore, these previews enable multilingual testing in a WYSIWYG environment and can also be used by reviewers. Feedback can be stored in comments, and communicated to the translators who then make the necessary changes within the context.
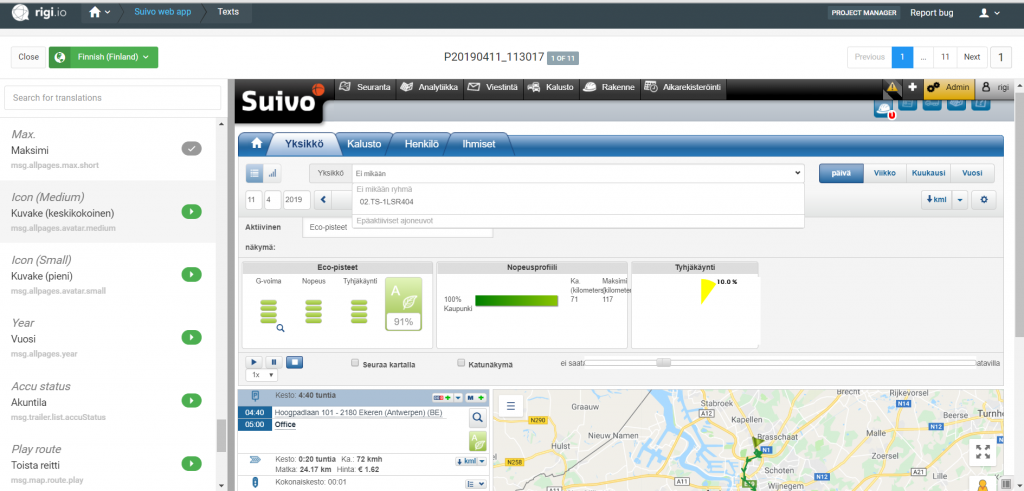
Rigi also allows for the automatic capturing of (localised) screenshots that can later be used in manuals or for online help. This avoids a lot of manual work when creating and translating technical documentation that comes with the software.
One of the ultimate goals is to make localization related tasks as independent from development as possible.
Rigi supports two concepts that are fundamental for a successful software localisation process: ID-based localisation and visual context.
- ID-based localisation: Rigi identifies the software strings based on their unique ID. Because of that, only new or edited texts will be marked as ‘to be translated’. This further improves consistency and allows each string to be presented within its context.
- Visual localisation: The quality and the volume are proportional to the necessary time and costs of the localisation project. With Rigi, you can easily create localisation sets with indexed previews. As a result, translators work in context (WYSIWYG) and can alter their translations depending on the function of the string.